跳跃表
跳跃表
: (skiplist)是一种有序的数据结构,支持平均O(logN)、最坏O(N)复杂度的节点查找,还可以通过顺序性操作来批量处理节点。大部分情况下,跳跃表的效率可以和平衡树相媲美,且实现更为简单。
Redis使用跳跃表作为有序集合键(zset)的底层实现之一,如果一个有序集合包含的元素数量较多,又或者有序集合中的元素成员(member)是比较长的字符串时,Redis就会使用跳跃表来作为有序集合键的底层实现。
例如
: fruit-price是一个有序集合键,这个有序集合以水果名为成员,水果价钱为分值,保存了130款水果的价钱
redis> ZRANGE fruit-price 0 2 WITHSCORES
1)"banana"
2)"5"
3)"cherry"
4)"6.5"
5)"apple"
6)"8"
redis> ZCARD fruit-price
(integer) 130
fruit-price有序集合的所有数据都保存在一个跳跃表里面,其中每个跳跃表节点(node)都保存了一款水果的价钱信息,所有水果按价钱的高低从低到高在跳跃表里面排序。
和链表、字典等数据结构被广泛地应用在Redis内部不一样,Redis只在两个地方用到了跳跃表,一个是实现有序集合键,另一个是在集群节点中用作内部数据结构,除此之外跳跃表在Redis中没有其他用途。
跳跃表原理
性质
:
- 由很多层结构组成;
- 每一层都是一个有序的链表,排列顺序为由高层到底层,都至少包含两个链表节点,分别是前面的head节点和后面的nil节点;
- 最底层的链表包含了所有的元素;
- 如果一个元素出现在某一层的链表中,那么在该层之下的链表也全都会出现(上一层的元素是当前层的元素的子集);
- 链表中的每个节点都包含两个指针,一个指向同一层的下一个链表节点,另一个指向下一层的同一个链表节点;

搜索
: 其基本原理就是从最高层的链表节点开始,如果比当前节点要大和比当前层的下一个节点要小,那么则往下找,也就是和当前层的下一层的节点的下一个节点进行比较,以此类推,一直找到最底层的最后一个节点,如果找到则返回,反之则返回空。

插入
: 既然要插入,首先需要确定插入的层数,这里有不一样的方法。1. 抛硬币法,只要是正面就累加,直到遇见反面才停止,最后记录正面的次数并将其作为要添加新元素的层;2. 统计概率,先给定一个概率p,产生一个0到1之间的随机数,如果这个随机数小于p,则将高度加1,直到产生的随机数大于概率p才停止,根据给出的结论,当概率为1/2或者是1/4的时候,整体的性能会比较好(其实当p为1/2的时候,也就是抛硬币的方法)。
当确定好要插入的层数以后,则需要将元素都插入到从最底层到第k层。
删除
: 在各个层中找到包含指定值的节点,然后将节点从链表中删除即可,如果删除以后只剩下头尾两个节点,则删除这一层。
跳跃表的实现
Redis的跳跃表由redis.h/zskiplistNode和redis.h/zskiplist两个结构定义,其中zskiplistNode结构用于表示跳跃表节点,而zskiplist结构则用于保存跳跃表节点的相关信息,比如结点的数量,指向表头节点和表位节点的指针等等。
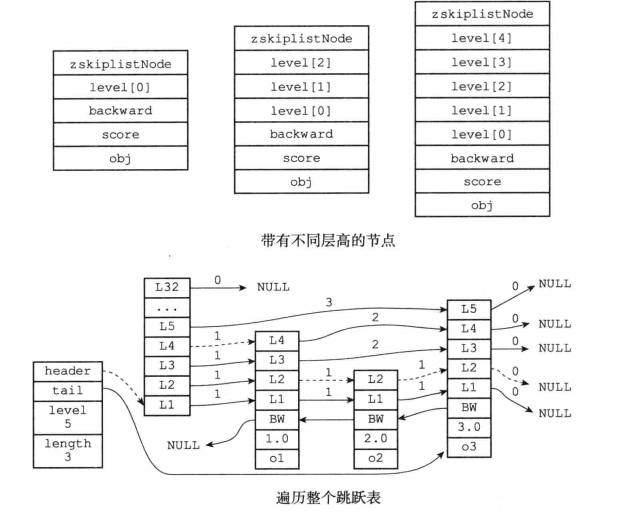
上图展示了一个跳跃表示例,位于图片最左边的是zskiplist结构,该结构包含以下属性:
- header:指向跳跃表的表头节点
- tail:指向跳跃表的表尾节点
- level:记录目前跳跃表内,层数最大的那个节点的层数(表头节点的层数不计算在内)
- length:记录跳跃表的长度,也即是,跳跃表目前包含节点的数量(表头节点不计算在内)
位于zskiplist结构右方的是四个zskiplistNode结构,该结构包含以下属性:
层(level):节点中用L1、L2、L3等字样标记节点的各个层,L1代表第一层,L2代表第二层,依次类推。每个层都带有两个属性:前进指针和跨度。前进指针用于访问位于表尾方向的其他节点,而跨度则记录了前进指针所指向节点和当前节点的距离。在上面的图片中,连线上带有数字的箭头就代表前进指针,而那个数字就是跨度。当程序从表头向表尾进行遍历时,访问会沿着层的前进指针进行。
后退(backward)指针:节点中用BW字样标记节点的后退指针,它指向位于当前节点的前一个节点。后退指针在程序从表尾向表头遍历时使用。
分值(score):各个节点中的1.0、2.0和3.0是节点所保存的分值。在跳跃表中,节点按各自所保存的分值从小到大排列。
成员对象(obj):各个节点中的o1、o2和o3是节点所保存的成员对象。
注意表头节点和其他节点的构造是一样的:表头节点也有后退指针、分值和成员对象,不过表头节点的这些属性都不会被用到,所以图中省略了这些部分,只显示了表头节点的各个层。
跳跃表节点
:1
2
3
4
5
6
7
8
9typedef struct zskiplistNode {
struct zskiplistNode *backward; //后退指针
double score;//分值
robj *obj;//成员对象
struct zskiplistLevel { //层
struct zskiplistNode *forward; //前进指针
unsigned int span; //跨度
} level[];
} zskiplistNode;
层:跳跃表节点的level数组可以包含多个元素,每个元素都包含一个指向其他节点的指针,程序可以通过这些层来加快访问其他节点的速度,一般来说,层的数量越多,访问其他节点的速度就越快。
每次创建一个新跳跃表节点的时候,程序根据幂次定律(power law,越大的数出现的概率越小)随机生成一个介于1和32之间的值作为level数组的大小,这个大小就是层的“高度”。
下图分别展示了三个高度为1层、3层和5层的节点,因为C语言的数组索引总是从0开始的,所以节点的第一层是level[0],而第二层是level[1],依次类推。前进指针
跨度:层的跨度(
level[i].span属性)用于记录两个节点之间的距离:两个节点之间的跨度越大,它们相距得就越远。指向NULL的所有前进指针的跨度都为0,因为它们没有连向任何节点。初看上去,很容易以为跨度和遍历操作有关,但实际上并不是这样的,遍历操作只使用前进指针就可以完成了,跨度实际上是用来计算排位(rank)的:在查找某个节点的过程中,将沿途访问过的所有层的跨度累计起来,得到的结果就是目标节点在跳跃表中的排位。后退指针:节点的后退指针(backward属性)用于从表尾向表头方向访问节点:跟可以一次跳过多个节点的前进指针不同,因为每个节点只有一个后退指针,所以每次只能后退至前一个节点。
分值和成员:节点的分值(score属性)是一个double类型的浮点数,跳跃表中的所有节点都按分值从小到大来排序。
节点的成员对象(obj属性)是一个指针,它指向一个字符串对象,而字符串对象则保存着一个SDS值。
在同一个跳跃表中,各个节点保存的成员对象必须是唯一的,但是多个节点保存的分值却可以是相同的:分至相同的节点将按照成员对象在字典中的大小来进行排序,成员对象较小的节点会排在前面(靠近表头的方向),而成员对象较大的节点则会排在后面(靠近表尾的方向)。
跳跃表
:1
2
3
4
5typedef struct zskiplist {
struct zskiplistNode *header, *tail; //header指向跳跃表的表头节点,tail指向跳跃表的表尾节点
unsigned long length; //记录跳跃表的长度,也即是,跳跃表目前包含节点的数量(表头节点不计算在内)
int level; //记录目前跳跃表内,层数最大的那个节点的层数(表头节点的层数不计算在内)
} zskiplist;
header和tail指针分别指向跳跃表的表头和表尾节点,通过这两个指针,程序定位表头节点和表尾节点的复杂度为O(1)。
通过length属性,可以在O(1)复杂度内返回跳跃表的长度。
level属性用于在O(1)复杂度内获取跳跃表中层高最大的那个节点的层数量(不计算表头节点的层高)。
总结
- 跳跃表是有序集合的底层实现之一
- Redis的跳跃表实现由
zskiplist和zskiplistNode两个结构组成,其中zskiplist用于保存跳跃表信息(表头节点、表尾节点、长度),而zskiplistNode则用于表示跳跃表节点 - 每个跳跃表节点的层高都是1至32之间的随机数
- 在同一个跳跃表中,多个节点可以包含相同的分值,但每个节点的成员对象(指向SDS的一个指针)必须是唯一的
- 跳跃表中的节点按照分值大小进行排序,当分值相同时,节点按照成员对象在字典序中的大小进行排序